Inteligencia artificial para el diagnóstico del cáncer de piel: un estudio de validación de algoritmos
Un artĂculo publicado en la ediciĂłn de aniversario de la EADV, Academia Europea de DermatologĂa y VenereologĂa, llamada JEACP y que hoy te ofrecemos para tu conocimiento y actualizaciĂłn
Utilidades
Warning: mt_rand(): max(-1) is smaller than min(0) in /var/www/vhosts/beautymarket.es/beautymed.es/ccss8/pgm/bannermanagement.php on line 35
Warning: mysql_fetch_row() expects parameter 1 to be resource, boolean given in /var/www/vhosts/beautymarket.es/beautymed.es/ccss8/pgm/bannermanagement.php on line 39

Warning: mt_rand(): max(-1) is smaller than min(0) in /var/www/vhosts/beautymarket.es/beautymed.es/ccss8/pgm/bannermanagement.php on line 35
Warning: mysql_fetch_row() expects parameter 1 to be resource, boolean given in /var/www/vhosts/beautymarket.es/beautymed.es/ccss8/pgm/bannermanagement.php on line 39
-
Warning: mt_rand(): max(-1) is smaller than min(0) in /var/www/vhosts/beautymarket.es/beautymed.es/ccss8/pgm/bannermanagement.php on line 35
Warning: mysql_fetch_row() expects parameter 1 to be resource, boolean given in /var/www/vhosts/beautymarket.es/beautymed.es/ccss8/pgm/bannermanagement.php on line 39
-
![Antioxidantes mitocondriales: Âżmoda o evoluciĂłn real?]()
Antioxidantes mitocondriales: Âżmoda o evoluciĂłn real?
-
![x]()
Cómo evitar el intrusismo en medicina estética y elegir un centro seguro
La demanda de tratamientos estéticos aumenta antes del verano, pero también lo hace el riesgo de acudir a centros no autorizados. Conocer cómo identificar un establecimiento sanitario y un profesional cualificado es clave para proteger la salud.
-
![x]()
Continúa la tendencia al alza en los tratamientos estéticos masculinos
El informe publicado detalla también las modalidades más demandadas entre los pacientes de sexo masculino
-
![x]()
Mesoterapia facial, el tratamiento de Beauty and Care para revitalizar la piel
Este tratamiento es uno de los mejores prevacaciones a base de vitaminas, ácido hialurónico, aminoácidos y oligoelementos inyectados en la dermis superficial de la piel
-
![x]()
América Latina lidera las operaciones de agrandamiento de pene
Alemania es el paĂs que registra más intervenciones quirĂşrgicas para agrandar y ensanchar el miembro viril. El nĂşmero de operaciones en todo el mundo continĂşa creciendo
-
![x]()
MarĂa Pombo, Jessica Goicoecha, Laura Escanes y Dulceida, los retoques estĂ©ticos de las influencers
Hoy, cuatro de nuestras socialitĂ©s más famosas nos descubren sus principales retoques estĂ©ticos y cĂłmo estos han cambiado su fisionomĂa... ¡a mejor!, por supuesto


12/12/2022

En este estudio de validaciĂłn de algoritmos sobre datos retrospectivos, los autores reprodujeron y evaluaron el rendimiento de la inteligencia artificial de vanguardia (redes neuronales convolucionales) para el diagnĂłstico del cáncer de piel. Aunque la inteligencia artificial de vanguardia supera a los dermatĂłlogos en la clasificaciĂłn de lesiones cutáneas basada en imágenes dentro de un entorno artificial, se necesitan datos adicionales y avances tecnolĂłgicos antes de la implementaciĂłn clĂnica.
Se espera que la incidencia de melanoma (MEL), el subtipo más mortal de cáncer de piel, se duplique antes de 2030. El diagnĂłstico preciso del cáncer de piel basado en un examen clĂnico y la dermatoscopia, una tĂ©cnica no invasiva, es difĂcil y requiere varios años de experiencia. Los primeros intentos de reemplazar a los mĂ©dicos competentes mediante la implementaciĂłn de algoritmos de diagnĂłstico basados en criterios visuales predefinidos fueron prometedores, sin embargo, ninguno de los mĂ©todos fue apropiadamente especĂfico, confiable y práctico para la implementaciĂłn clĂnica. Esto cambiĂł en 2017 cuando las redes neuronales convolucionales (CNN), un subtipo de inteligencia artificial (IA), realizaron diagnĂłsticos de cáncer de piel a nivel dermatĂłlogo.11 Varios estudios secuenciales han confirmado que las CNN superan a los mĂ©dicos en el diagnĂłstico de cáncer de piel basado en imágenes dentro de un entorno artificial controlado y experimental.
Estos resultados han llevado a una cadena de historias sensacionales que afirman que la IA ha superado a los dermatĂłlogos en el diagnĂłstico del cáncer de piel. Las posibles consecuencias de la implementaciĂłn en el mundo real de los algoritmos de CNN no están claras, pero los hallazgos preliminares sugieren que serĂan poco confiables y sustancialmente menos precisos que los mĂ©dicos en la evaluaciĂłn clĂnica de las lesiones cutáneas.
A diferencia de los humanos, los algoritmos no pueden evaluar y tratar las lesiones cutáneas y el paciente acompañante desde una perspectiva holĂstica. Además, se sabe que las CNN generalizan mal hacia las nuevas fuentes de datos y son sensibles a los sesgos, el sobreajuste y las correlaciones espurias introducidas a travĂ©s de su conjunto de datos de entrenamiento.4, 21-28 Varios estudios recientes sugieren que las CNN pueden proporcionar un valor clĂnico significativo si se usan en cooperaciĂłn con un mĂ©dico calificado para tareas limitadas, como diferenciar entre nevos y MEL. Sin embargo, los medios de comunicaciĂłn y varias compañĂas comerciales sugieren el uso de IA para diagnĂłsticos autĂłnomos automatizados de lesiones cutáneas dirigidos por pacientes o mĂ©dicos. Este estudio tiene como objetivo medir y explicar la generalizaciĂłn y el rendimiento de un conjunto (grupo) de vanguardia de CNN para el diagnĂłstico y la clasificaciĂłn automatizados independientes del cáncer de piel, de una manera simple y clĂnicamente significativa.
Materiales y MĂ©todos
En este estudio de validaciĂłn de algoritmos, reproducimos un conjunto de CNN, con rendimiento a nivel de dermatĂłlogo en el diagnĂłstico de cáncer de piel, en lo sucesivo denominado conjunto de colaboraciĂłn internacional de imágenes de piel (ISIC). Exploramos la generalizaciĂłn del conjunto ISIC hacia nuevos dispositivos de captura de imágenes (cámaras, dermoscopios, otros dispositivos) y su utilidad clĂnica en el diagnĂłstico de MEL y el triaje del cáncer de piel. El conjunto fue entrenado en imágenes dermatoscĂłpicas anotadas del repositorio de imágenes de cĂłdigo abierto llamado archivo ISIC. Nuestro grupo desarrollĂł un nuevo conjunto de datos llamado AISC-2021, que utilizamos durante las simulaciones clĂnicas para probar la generalizaciĂłn del conjunto. Utilizamos el marco de ciencia de datos de cĂłdigo abierto mantenido continuamente PyTorch.29 El estudio recibiĂł una exenciĂłn Ă©tica del ComitĂ© de Ética DanĂ©s (jr. nr. H-20066667) y se llevĂł a cabo segĂşn los principios de la DeclaraciĂłn de Helsinki. Las autoridades danesas de datos de salud y la Agencia de ProtecciĂłn de Datos aprobaron el acceso, la anotaciĂłn, la anonimizaciĂłn, el manejo y el almacenamiento de imágenes dermatoscĂłpicas (jr. nr. 21/5103 y 18/53664).
Datos
Este estudio incluyĂł dos conjuntos de datos de imágenes de lesiones cutáneas, el conjunto de datos ISIC-2019 (ISIC challenge 2019) del archivo ISIC y nuestro conjunto de datos AISC-2021. Ambos conjuntos de datos consisten en imágenes dermatoscĂłpicas anotadas con una de las siguientes ocho etiquetas diagnĂłsticas: queratosis actĂnica/enfermedad de Bowen (QA), carcinoma de cĂ©lulas basales (BCC), lesiones queratinocĂticas benignas (BKL), dermatofibroma (DF), MEL, nevo melanocĂtico (NV), carcinoma de cĂ©lulas escamosas (SCC) y lesiĂłn vascular (VASC).
Conjunto de datos ISIC-2019
El conjunto de datos ISIC-2019 consiste en un conjunto de datos de capacitaciĂłn (ISIC-2019-train) y prueba (ISIC-2019-test). ISIC-2019-train se puede descargar del sitio web del desafĂo ISIC 2019 (https://challenge2019.isic-archive.com). ISIC-2019-test está disponible a travĂ©s de una tabla de clasificaciĂłn en lĂnea (https://challenge.isic-archive.com/leaderboards/live), donde cualquiera puede publicar y probar sus algoritmos. El conjunto de datos de la CIIU-2019 se ha descrito detalladamente en otra parte.30, 31 Para simplificar, se excluyeron las imágenes ISIC-2019 con un diagnĂłstico desconocido (clase desconocida).
Conjunto de datos AISC-2021
El conjunto de datos AISC-2021 consta de 27.638 imágenes dermatoscĂłpicas anotadas de 15.552 lesiones cutáneas pigmentadas de 7122 pacientes. Las imágenes fueron capturadas por enfermeras y mĂ©dicos del Departamento de DermatologĂa y Centro de Alergias del Hospital Universitario de Odense, Dinamarca, del 1 de septiembre de 2010 al 8 de mayo de 2021. Todas las imágenes dermatoscĂłpicas fueron fotografiadas utilizando dermoscopios digitales (Medicam 800 y 1000, Fotofinder Systems GmbH). Los diagnĂłsticos clĂnicos (n = 9073) e histopatolĂłgicos (n = 6479) se fusionaron manualmente con las imágenes dermatoscĂłpicas, y se agregĂł el grosor de Breslow para las MEL.
Los diagnĂłsticos clĂnicos consistieron en un juicio conjunto de dos a tres mĂ©dicos, de los cuales al menos uno era un dermatĂłlogo certificado por la junta. No hubo datos disponibles sobre el origen Ă©tnico de los pacientes, el tipo de piel de Fitzpatrick, la calidad de la imagen, el tipo de dermatoscopia (polarizada/no polarizada) o la presencia de cabello y tatuajes. La mayorĂa de las imágenes dermatoscĂłpicas fueron polarizadas y fotografiadas despuĂ©s de la hidrataciĂłn con etanol de la piel. Las reglas dermatoscĂłpicas no estaban presentes en las imágenes dermatoscĂłpicas, y se podĂan encontrar Ăşlceras o cicatrices en una minorĂa de las imágenes. Todas las lesiones cutáneas en el conjunto de datos AISC-2021 se registraron antes de la escisiĂłn o como parte de un programa de seguimiento con dermatoscopia secuencial para descartar neoplasias malignas.
Creamos un entrenamiento y dos conjuntos de datos de prueba a partir de los datos AISC-2021; AISC-2021-train, AISC-2021-test y AISC-2021-MEL (melanoma). El conjunto de datos de prueba AISC-2021 se construyó con la misma distribución de diagnósticos que el conjunto de datos de prueba ISIC-2019, asegurando que pudiéramos probar la generalización de los algoritmos en lugar de sobreajustar el sesgo. Para evitar la fuga de datos entre los conjuntos de datos de entrenamiento y prueba, dividimos los datos a nivel de lesión y realizamos un análisis posterior a la división de si las imágenes estaban presentes en ambos conjuntos de datos.
CapacitaciĂłn y evaluaciĂłn comparativa del conjunto CIIU
El conjunto ISIC consistiĂł en un grupo de CNN entrenados utilizando un mĂ©todo previamente descrito desarrollado por el equipo ganador (Gessert et al.) en el desafĂo ISIC en 2019.4, 30 El desafĂo ISIC 2019 fue un concurso internacional de algoritmos para el diagnĂłstico de lesiones cutáneas que atrajo a laboratorios cientĂficos y comerciales de aprendizaje automático de todo el mundo. Notamos el sobreajuste desde el principio, lo que nos llevĂł a entrenar las CNN del conjunto para 60 en lugar de las 100 Ă©pocas descritas originalmente por Gessert et al. El tĂ©rmino "Ă©poca" describe el nĂşmero de veces que los algoritmos se entrenan en todo el conjunto de datos de entrenamiento. Además, Gessert et al. complementaron los datos de entrenamiento con datos adicionales, a los que no tuvimos acceso. Cuando el conjunto ISIC terminĂł de entrenar, comparamos su interpretaciĂłn con el conjunto original de Gessert et al. para confirmar una reproducciĂłn exitosa.
Generalizabilidad del conjunto CIIU
La generalizaciĂłn del conjunto ISIC se probĂł mediante una comparaciĂłn de su rendimiento en dos conjuntos de datos de prueba, uno con imágenes de las mismas fuentes que los datos de entrenamiento (prueba ISIC-2019) y otro con imágenes de una nueva fuente de datos (AISC-2021-test). Para validar si las diferencias potenciales se debieron a una generalizaciĂłn deficiente, entrenamos un conjunto idĂ©ntico de CNN en un conjunto de datos de entrenamiento mixto que incluĂa imágenes de ambas fuentes de datos (ISIC-2019-train y AISC-2021-train) y probamos su rendimiento (ISIC & AISC ensemble) en ambos conjuntos de datos de prueba (ISIC-2019-test y AISC-2021-test), ver Figura 1.
 Figura 2.
Figura 2.
Simulaciones clĂnicas
Probamos el rendimiento del conjunto ISIC a travĂ©s de diferentes interpretaciones de su resultado de probabilidad en dos simulaciones clĂnicas: diagnĂłstico MEL y triaje del cáncer de piel (Figura 2).
DiagnĂłstico MEL en las simulaciones clĂnicas
El resultado del conjunto ISIC consistió en estimaciones de probabilidad para cada clase de diagnóstico, por ejemplo, 80% MEL, 15% NV y 4% DF. Diagnosticamos cada lesión cutánea durante la primera simulación basada en la clase diagnóstica que logró la estimación de probabilidad más alta, ver Figura 3a. Todas las MELs (invasivas e in situ) del conjunto de datos AISC-2021 (AISC-2021-MEL) se diagnosticaron en esta simulación. Se examinó la correlación entre la probabilidad de MEL y el espesor de Breslow para probar si la precisión del conjunto ISIC era superior para los MEL gruesos en comparación con los delgados.
Triaje del cáncer de piel en las simulaciones clĂnicas
Determinamos quĂ© umbrales de probabilidad para BCC, MEL y SCC, que produjeron una sensibilidad del 99,1% en el conjunto de datos de prueba ISIC-2019, ver Figura 3b, c. Se considerĂł aceptable una sensibilidad del 99,1%, ya que corresponde a la sensibilidad del manejo clĂnico de un dermatĂłlogo experto.32 Las lesiones se consideraron sospechosas si las estimaciones de probabilidad para MEL, BCC o SCC excedieron sus umbrales predefinidos. Utilizamos todo el conjunto de datos AISC-2021 para evaluar la sensibilidad y especificidad de la interpretaciĂłn del triaje.
EstadĂstica
Todos los análisis estadĂsticos se realizaron en SAS Studio 3.8 (SAS Institute) y Excel 2016 (Microsoft). Las áreas bajo las curvas caracterĂsticas operativas del receptor (AUC ROC) se compararon mediante la prueba de Hanley-McNeil,33 y la correlaciĂłn entre el espesor de Breslow y la probabilidad de MEL se evaluĂł mediante la prueba de correlaciĂłn de Pearson. p Los valores inferiores a 0,05 fueron considerados significativos (Tabla 1).
Resultados
Benchmarking y generalizabilidad.
El rendimiento de nuestro conjunto (conjunto ISIC) en la prueba ISIC-2019 fue comparable (Δ ROC AUC = 0.004, p = 0.059) al conjunto original de Gessert et al.30 Las AUC ROC del conjunto para NV, MEL y AK fueron significativamente más bajas en la prueba AISC-2021 en comparaciĂłn con el conjunto de datos de prueba ISIC-2019, ver Figura 4 y Tabla 2. El conjunto combinado ISIC y AISC tuvo un rendimiento notablemente mejor que el conjunto ISIC en ambos conjuntos de datos de prueba (prueba ISIC-2019 y prueba AISC-2021). De hecho, el conjunto ISIC y AISC mostrĂł signos de sobreajuste AISC-2021, con una mejora desproporcionadamente grande en la prueba AISC-2021 en comparaciĂłn con la prueba ISIC-2019, ver Tabla 2.
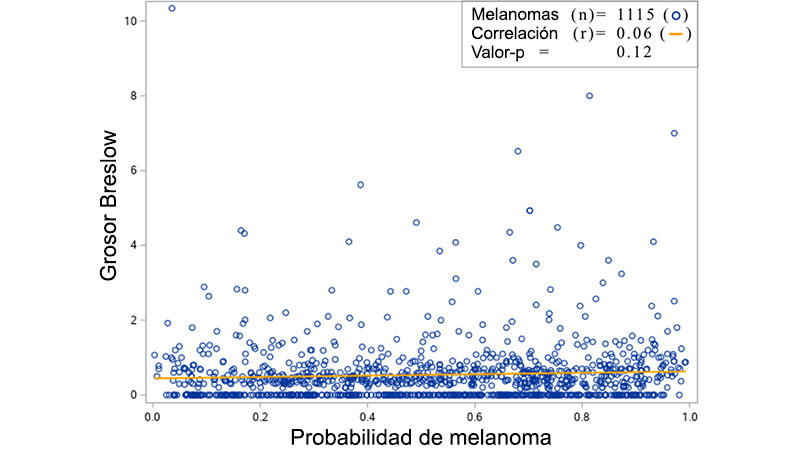 Figura 5.
Figura 5.
DiagnĂłstico MEL
El conjunto ISIC tuvo una sensibilidad MEL del 68,9% y, por lo tanto, diagnosticĂł errĂłneamente el 31,1% de los MEL (in situ e invasivos). No hubo correlaciĂłn significativa entre el espesor de Breslow de los MELs y la probabilidad de MEL proporcionada por el conjunto (r = 0,06, p = 0,12), ver Figura 5.
Triaje del cáncer de piel
Con umbrales de probabilidad predefinidos de 3,6%, 3,6% y 0,6% para MEL, BCC y SCC, el conjunto clasificĂł 1138 (7,3%) de las lesiones AISC-2021 como no sospechosas y las 14.413 restantes (92,7%) lesiones como sospechosas de malignidad. Cinco (0,4%) de las lesiones descartadas eran malignas, y 1687 (11,7%) de las lesiones sospechosas eran MEL, BCC o SCC. Los cinco tumores malignos descartados incorrectamente fueron cuatro CCB y un CCE. La simulaciĂłn de triaje arrojĂł una sensibilidad y especificidad de 99,7% y 8,2%, respectivamente.
DiscusiĂłn
Este estudio evaluĂł y visualizĂł dos trampas crĂticas con respecto a los conjuntos de CNN para el diagnĂłstico del cáncer de piel, a saber, la generalizaciĂłn y la compensaciĂłn sensibilidad-especificidad. Encontramos que un conjunto de CNN de vanguardia con rendimiento a nivel dermatĂłlogo dentro de un entorno experimental altamente controlado se generalizĂł mal hacia imágenes de nevos, MELs y queratosis actĂnicas que se habĂan capturado utilizando diferentes dispositivos de captura de imágenes (cámaras y dermoscopios) que el conjunto de datos de entrenamiento. El conjunto clasificĂł errĂłneamente el 31,1% de todos los MELs durante la simulaciĂłn diagnĂłstica, independientemente de su grosor Breslow. Además, el conjunto clasificĂł menos de una dĂ©cima parte (7,3%) de las 15.552 lesiones AISC-2021 como no sospechosas durante la simulaciĂłn de triaje. En otras palabras, los algoritmos serĂan inĂştiles para el diagnĂłstico automatizado independiente y el triaje en manos de operadores no capacitados, ya que esto darĂa como resultado un gran nĂşmero de MEL (diagnĂłsticos) descartados o lesiones cutáneas benignas referidas (triaje).
La generalizaciĂłn del conjunto ISIC hacia los datos AISC-2021 fue pobre, a pesar de haber sido entrenado en un conjunto de datos de entrenamiento deliberadamente heterogĂ©neo (ISIC-2019-train) con imágenes preprocesadas manualmente de mĂşltiples clĂnicas y departamentos de cáncer de piel.30, 31 El rendimiento de los algoritmos en ambos conjuntos de datos de prueba mejorĂł significativamente cuando los datos de AISC-2021 se incluyeron en el conjunto de datos de entrenamiento, aunque los algoritmos se sobreajustaron al conjunto de datos AISC-2021. Nuestros resultados fueron confirmados en una publicaciĂłn reciente de Combalia et al. que examinĂł la generalizaciĂłn de los tres algoritmos principales del desafĂo ISIC 2019. La precisiĂłn diagnĂłstica de los algoritmos se redujo en más del 20% cuando se les pidiĂł que diagnosticaran lesiones cutáneas de nuevas fuentes. Estos resultados son significativos, ya que los errores sistemáticos causados por la incapacidad de los algoritmos para generalizar podrĂan resultar en resultados fatales para los pacientes si los mĂ©dicos y las enfermeras dependen totalmente de las predicciones del algoritmo. El trabajo relacionado de cardiologĂa ha demostrado que los mĂ©dicos olvidan rápidamente cĂłmo interpretar los electrocardiogramas cuando se implementan interpretaciones automatizadas.
Del mismo modo, Tschandl y sus colegas demostraron recientemente que los mĂ©dicos sin experiencia confĂan ciegamente en los algoritmos de diagnĂłstico para el diagnĂłstico del cáncer de piel. Probamos la generalizaciĂłn de los algoritmos utilizando dos conjuntos de datos de prueba que eran casi idĂ©nticos, excepto por los dispositivos utilizados para capturar las imágenes dermatoscĂłpicas. En un entorno clĂnico natural, diferencias de color sutiles similares podrĂan ser causadas fácilmente por diodos dermatoscĂłpicos vacilantes, nuevos dermoscopios, nuevos dispositivos de cámara o actualizaciones de software de cámara.
La generalizaciĂłn de los algoritmos de CNN se puede mejorar aumentando el tamaño y la heterogenicidad de los conjuntos de datos de entrenamiento, abarcando asĂ todos los datos demográficos de los pacientes, diagnĂłsticos y modalidades de captura de imágenes que se encuentran dentro del entorno clĂnico previsto.25 La comunidad ISIC se esfuerza por proporcionar un conjunto de datos heterogĂ©neo a travĂ©s del repositorio de imágenes de archivo ISIC de cĂłdigo abierto en continuo crecimiento. Sin embargo, no hay garantĂa de que el archivo de la CIIU o conjuntos de datos similares sean lo suficientemente grandes o heterogĂ©neos como para apoyar el desarrollo de algoritmos de diagnĂłstico genuinamente confiables para el ecosistema clĂnico en rápida evoluciĂłn. Por esta razĂłn, sugerimos que los algoritmos de diagnĂłstico se validen prospectivamente para el entorno previsto antes de la implementaciĂłn clĂnica y continuamente despuĂ©s de eso a intervalos predeterminados para garantizar una rápida identificaciĂłn y mitigaciĂłn de los cambios entre los datos de entrada y el conjunto de datos de entrenamiento de los algoritmos.

Alternativamente, el mĂ©todo y los dispositivos utilizados para capturar imágenes clĂnicas deben estandarizarse, asegurando una alineaciĂłn perfecta entre los datos de entrada y los datos de entrenamiento de los algoritmos.36 Los márgenes de seguridad serĂan microscĂłpicos para los enfoques que se basan en la estandarizaciĂłn, ya que la precisiĂłn de los algoritmos sobreajustados disminuirĂa notablemente cuando se introduzcan problemas tĂ©cnicos menores o errores humanos.
Los algoritmos de CNN realizan diagnĂłsticos de cáncer de piel más precisos que los dermatĂłlogos dentro de un entorno de prueba artificial y altamente controlado.Sin embargo, en la vida real, los mĂ©dicos recopilan datos de diagnĂłstico adicionales, consultan con colegas, actĂşan con cautela en caso de duda y hacen un seguimiento de las lesiones cutáneas sospechosas. En este estudio, los algoritmos "superiores" clasificaron errĂłneamente 347 (31,1%) de los 1115 MEL, todos diagnosticados y tratados por los mĂ©dicos del Departamento de DermatologĂa y Centro de Alergias del Hospital Universitario de Odense.
Para este estudio, elegimos intencionalmente un umbral de triaje muy seguro (sensibilidad: >99,1%), correspondiente al de un dermatĂłlogo experto con todas las opciones estándar de tratamiento y seguimiento a su disposiciĂłn. Las simulaciones representaban un escenario clĂnico en el que el operador del algoritmo tenĂa poca o ninguna experiencia en el diagnĂłstico del cáncer de piel, por ejemplo, un entorno de atenciĂłn primaria. No habĂa mecanismos de seguridad externos, como la supervisiĂłn de un experto en el dominio, dentro del entorno clĂnico simulado y, por lo tanto, priorizamos la seguridad en lugar de la efectividad. SegĂşn lo planeado, los algoritmos proporcionaron un triaje seguro (sensibilidad del 99,7%) pero ineficaz (8,2% de especificidad) del cáncer de piel. La especificidad fue inaceptablemente baja para el contexto clĂnico no especializado previsto. Si se implementan, es probable que los algoritmos impulsen un mayor nĂşmero de derivaciones dermatolĂłgicas benignas innecesarias, lo que sobrecargarĂa aĂşn más una especialidad ya tensa.
Cuando las soluciones tecnolĂłgicas como la teledermatologĂa reducen el esfuerzo relacionado con las segundas opiniones dermatolĂłgicas para las lesiones cutáneas, los proveedores de atenciĂłn primaria solicitan significativamente más consultas dermatolĂłgicas.38 La utilidad clĂnica de un resultado binario "sospechoso" o "no sospechoso" es cuestionable, ya que los diversos subtipos de afecciones de la piel requieren diferentes estrategias de manejo, tratamiento y comunicaciĂłn con el paciente.39-41 Finalmente, hay poco valor educativo en un algoritmo de triaje que marca el 92,7% de todas las lesiones cutáneas como "sospechosas".
Muchas MELs (in situ e invasivas) son lesiones melanocĂticas malignas benignas o de bajo grado potencialmente sobrediagnosticadas, y este tambiĂ©n puede ser el caso de algunos de los MEL AISC-2021. Sin embargo, el grosor de Breslow es un buen marcador pronĂłstico para la mortalidad y recurrencia de MEL, y por lo tanto, lo consideramos un proxy inverso para el sobrediagnĂłstico.No hubo correlaciĂłn entre el grosor Breslow de los MEL y las estimaciones de probabilidad del conjunto ISIC para MEL, lo que sugiere que los MEL se clasificaron errĂłneamente independientemente de si fueron potencialmente sobrediagnosticados o no.
Este estudio tuvo varias limitaciones. Primero, intentamos simular la implementaciĂłn clĂnica de algoritmos automatizados para el diagnĂłstico de MEL y el triaje del cáncer de piel en un entorno de atenciĂłn primaria. Sin embargo, nuestro conjunto de datos de simulaciĂłn (AISC-2021) provino de un departamento especializado para el diagnĂłstico de cáncer de piel donde todas las lesiones registradas eran lo suficientemente interesantes o sospechosas como para justificar un registro de imagen. El conjunto de datos AISC-2021 está muy sesgado hacia lesiones malignas y atĂpicas, similar al conjunto de datos ISIC-2019. Se teoriza que el conjunto CIIU funcionarĂa significativamente peor en un entorno de atenciĂłn primaria donde la mayorĂa de las lesiones son benignas. En segundo lugar, se desconoce la dificultad promedio del conjunto de datos AISC-2021, ya que no hubo evaluadores humanos en este estudio. El conjunto de datos AISC-2021 incluyĂł diagnĂłsticos más benignos que el ISIC-2019, lo que puede indicar que fue más fácil que el conjunto de datos ISIC-2019. En tercer lugar, este estudio investigĂł diagnĂłsticos automatizados independientes de CNN en manos de mĂ©dicos sin experiencia. Sin embargo, las CNN para la asistencia clĂnica entre mĂ©dicos calificados y el aumento de la capacitaciĂłn de los mĂ©dicos junior parecen tener un potencial clĂnico mucho mayor.
En resumen, este estudio examinĂł la generalizaciĂłn y el rendimiento clĂnico de un conjunto CNN de vanguardia descrito anteriormente para el diagnĂłstico del cáncer de piel. Los algoritmos se generalizaron mal hacia nuevos formatos de imagen y realizaron diagnĂłsticos MEL y triaje del cáncer de piel significativamente peores que los mĂ©dicos.
Autores: Niels K. Ternov | Anders N. Christensen | Peter J. T. Kampen | Gustav Als | Tine Vestergaard | Lars Konge | Martin Tolsgaard | Lisbet R. Hölmich | Pascale Guitera | Annette H. Chakera | Morten R. Hannemose.
Nota.
"En octubre celebramos el primer aniversario de la revista de acceso abierto de la Academia y nos sentimos honrados por el creciente nĂşmero de presentaciones interesantes que recibimos. Agradecemos a nuestros colaboradores por su confianza en la elecciĂłn del JEACP como hogar para sus publicaciones, asĂ como a nuestros revisores y al Equipo Editorial por su continuo apoyo para garantizar un proceso de revisiĂłn por pares exhaustivo y rápido." (EADV, Academia Europea de DermatologĂa y VenereologĂa)
En este nĂşmero, encontrarás artĂculos originales sobre psoriasis, dermatitis atĂłpica, inteligencia artificial y otros temas candentes. Espero que disfrute explorando este tema y buceando en informes de casos interesantes y casos de cuestionarios; particularmente la serie de casos relacionados con las caracterĂsticas de ultrasonido ecográfico del brazo COVID.

- Comparte este artĂculo
-

-

-

-

Recomendamos